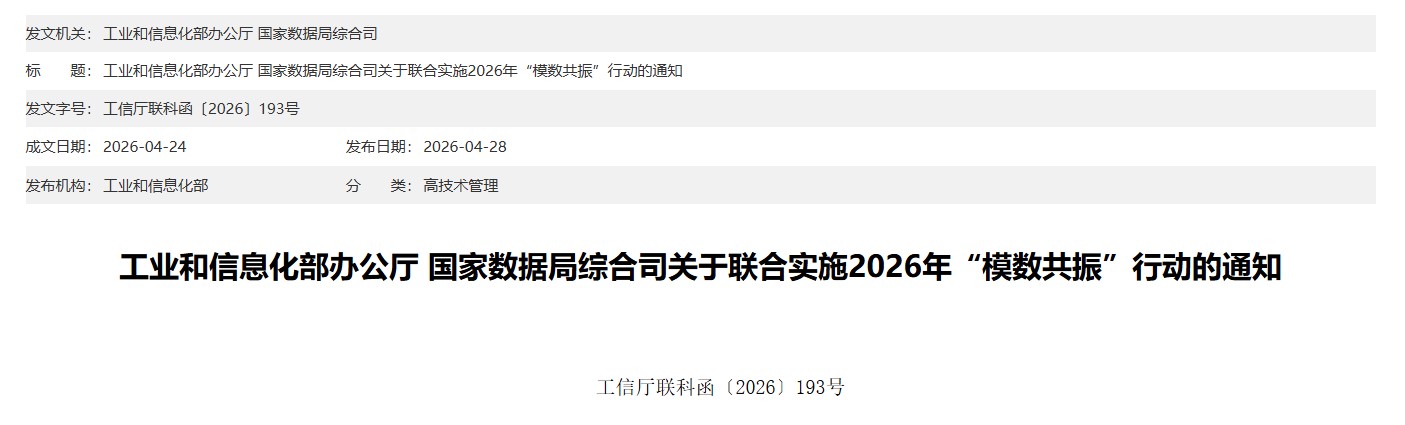
工信部与国家数据局联合通知
4月28日,工信部与国家数据局联合发布了2026年“模数共振”行动,为产业AI的系统化建设释放出新的政策信号。行动面向钢铁、石化、有色、汽车、医疗装备、电力装备等20个行业,明确提出构建行业通识数据集、行业专识数据集、行业模型和特色智能体,推动形成“数据-模型-场景应用”的良性循环。在一个AI Agent密集发布、行业每天都被新模型刷屏的五月,这份文件来得不算高调。但如果你仔细读完,会发现它指向了一个行业讨论了很久、却始终没有标准答案的问题:通用大模型已经能写诗、能编程、能通过律师资格考试了,但把它扔进一条真实的选矿产线,或者一套复杂的保险理赔流程里,它凭什么“懂行”?因为产业现场里的问题,不是开放式问答。
它有对象,有关系,有流程,有责任边界,还有大量不能出错的规则。
这也是“模数共振”真正值得关注的地方。
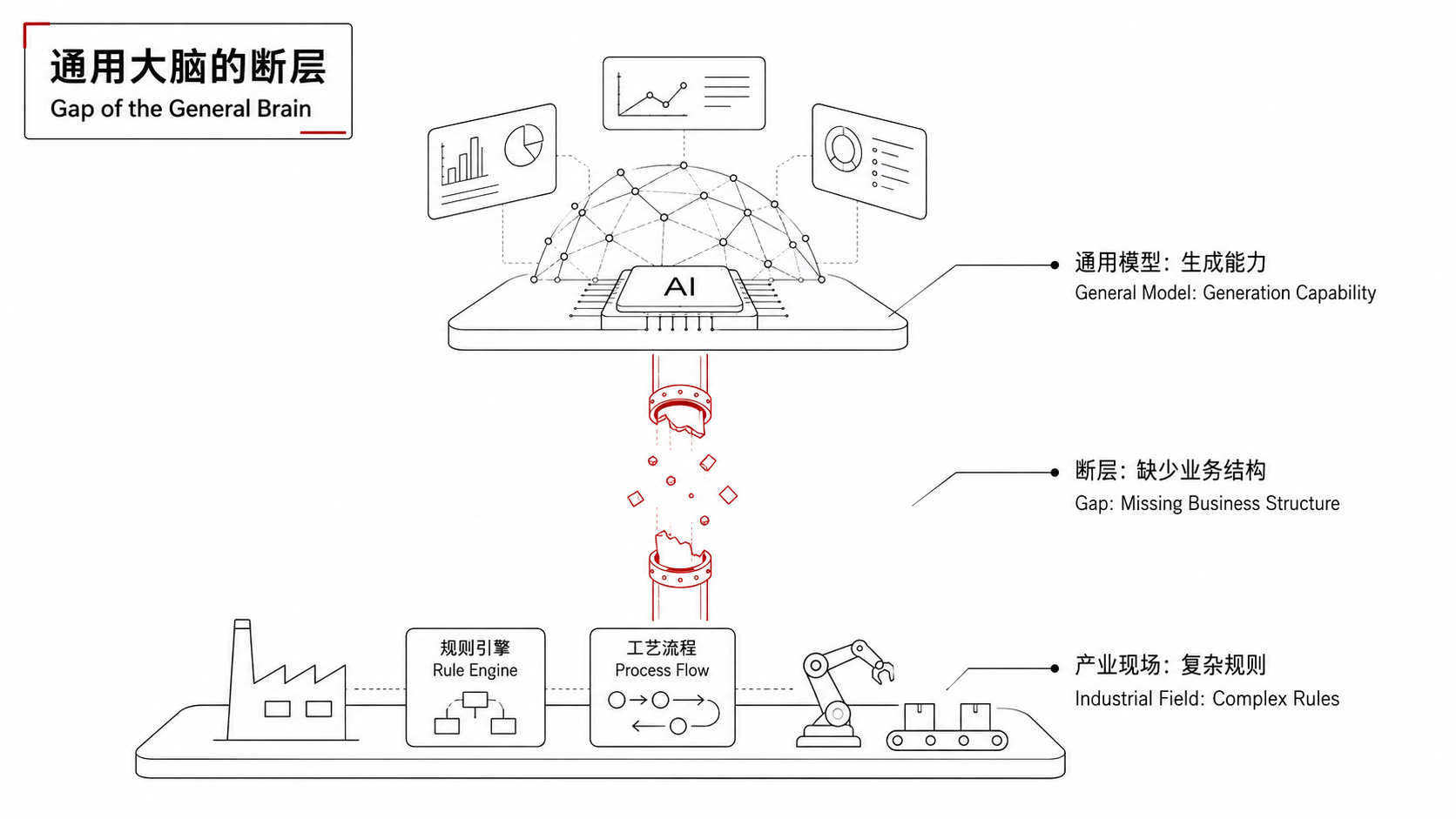
不久前,DeepSeek V4发布,1.6万亿参数、百万token上下文、Agent能力达到开源最高水平,推理性能逼近国际顶尖闭源模型。行业一片沸腾,券商连夜出报告,把2026年下半年定义为“国产算力规模化放量的重要窗口”。但热闹之下,一个冷问题一直悬着:参数再大、上下文再长,模型依然不知道什么是“球磨机溢流细度异常”,也不理解“理赔触发规则里的等待期叠加逻辑”。这不是模型不够聪明。相反,它太聪明了——聪明到在你让它写一篇产业分析时,它能用流畅的语言编织出一个看起来逻辑自洽、实则事实错漏百出的答案。用一个词概括这种尴尬:“有智无识”。有推理能力,但缺乏对具体行业的事实边界、业务流程和因果关系的真正理解。
行业里有人打了个比方:这就像请了一个智商180的天才来做你的技术总监,他没在你的车间里待过一天,没看过一页操作规程,但你期待他上任第一周就能给出产线优化方案。
很多企业已经踩过这个坑了。在复杂业务环境中,单纯增加数据量、扩展指标或叠加模型,并不必然带来更高质量的分析。
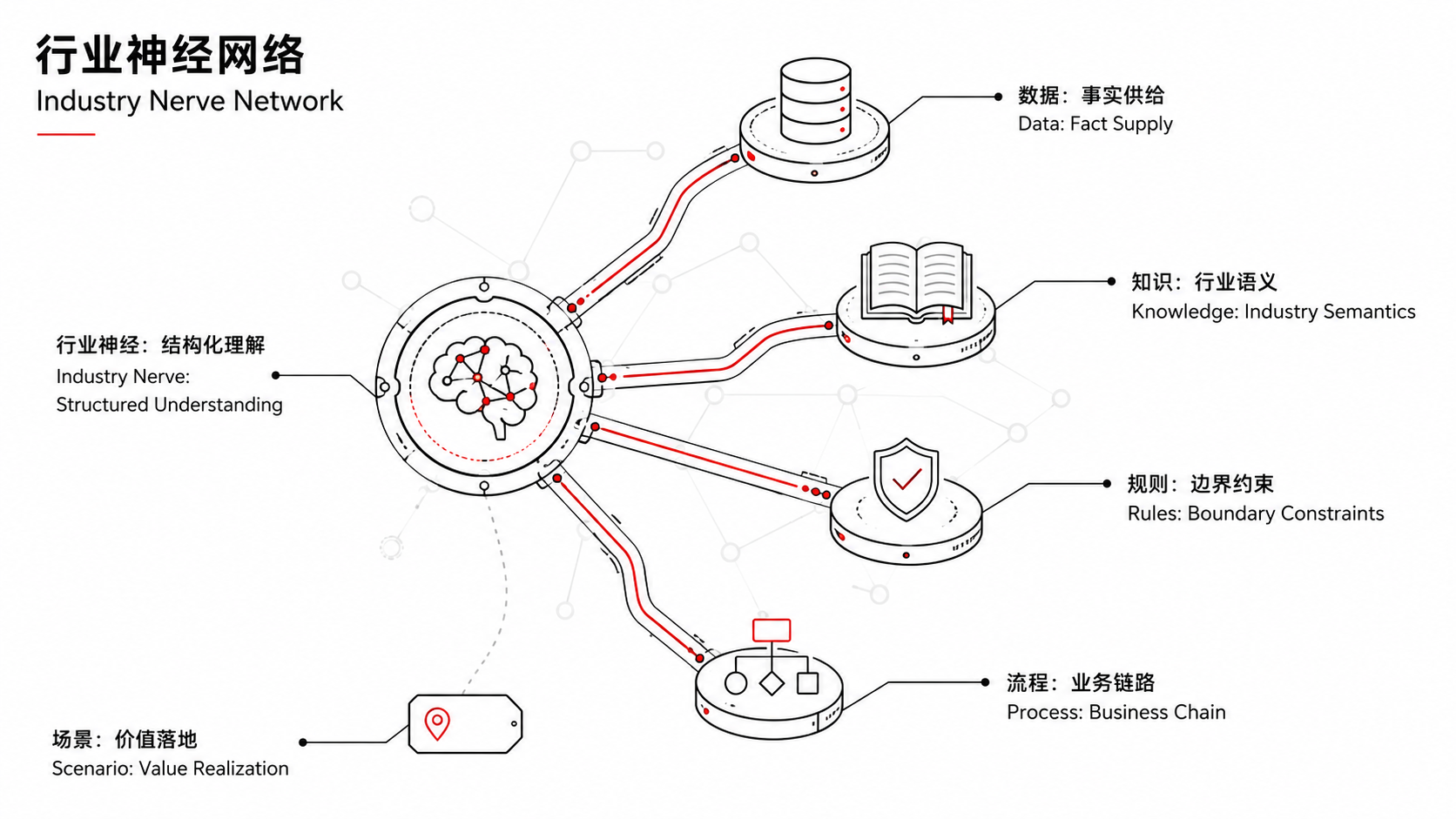
讨论进入这个阶段,一个认知的转折就出现了。过去两年,整个AI产业的竞争重心几乎都在“大脑”上——谁的参数更多,谁的推理更强,谁的上下文更长。但当一个又一个通用大模型开始逼近瓶颈,“智力”本身正在变成基础能力,真正的稀缺品换成了别的:让模型理解业务关系、事实边界和产业规则的“行业神经”。
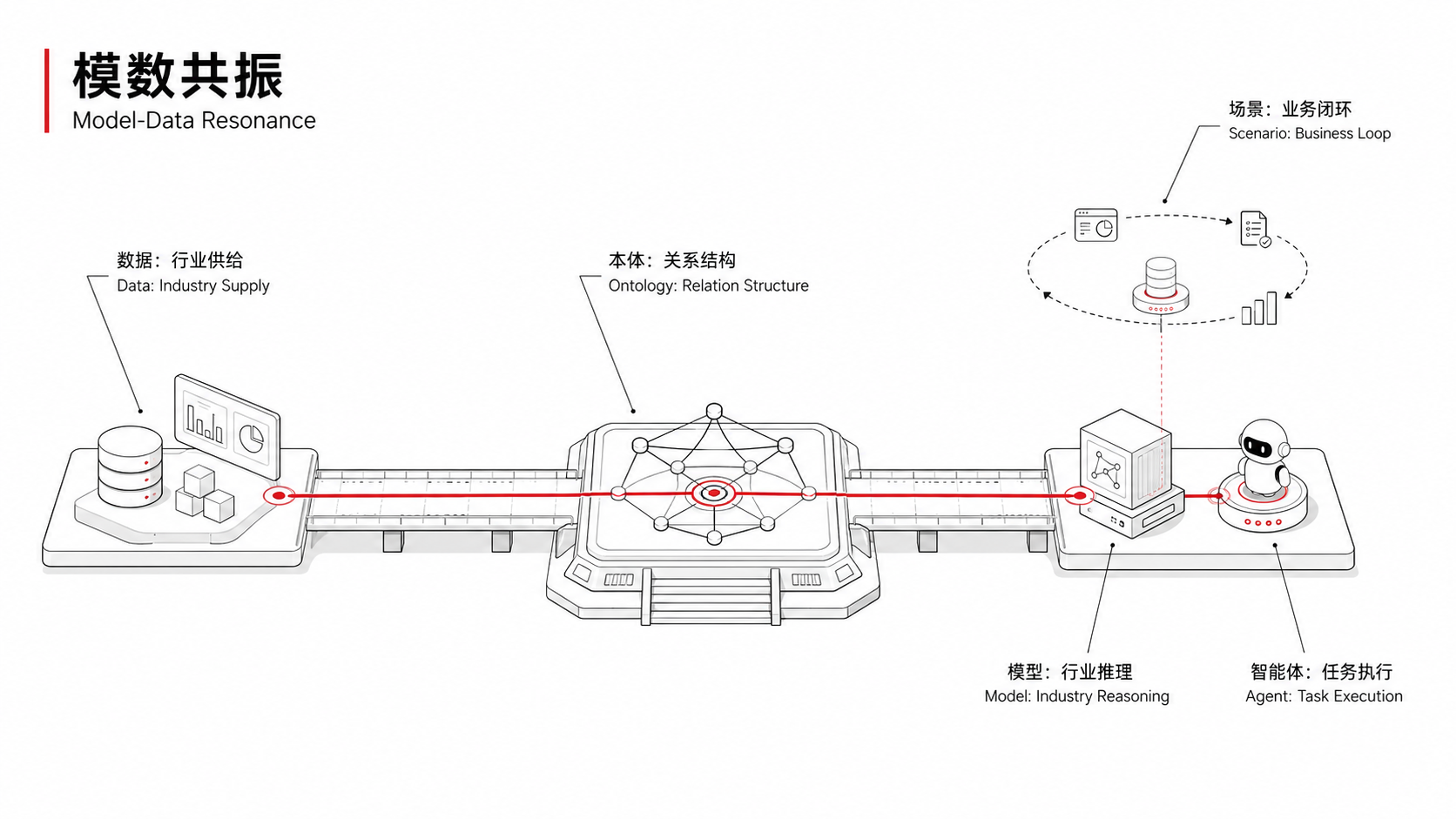
这也是“模数共振”行动最值得注意的地方。它提的不是“给每个行业训一个大模型”,而是构建“行业通识数据集+行业专识数据集+行业模型+特色智能体”的完整体系。“数据集”被放在了“模型”前面。政策指向了一个明确的方向:行业AI的瓶颈不在模型层,在数据层和知识层。你能不能把散落在操作规程、专家经验、设备手册、历史故障记录里的知识,整理成机器能理解的结构化体系,决定了你的AI到底是真能用,还是一个昂贵的摆设。
而这一步,恰恰是被“参数崇拜”掩盖太久的盲区。
如果你关注最近几个月的行业动向,会发现这种认知正在加速形成。腾讯云宣布AI算力价格上调5%,智谱GLM的Coding Plan涨幅30%-100%,行业从“免费试用”的狂欢里醒过来,开始认真算每个Token的投资回报率。智谱CEO张鹏把涨价定性为“回归正常的商业价值”。潜台词是:企业不会再为炫技买单了,他们只愿意为“可量化的业务增量”付费。硅谷那边也是一样的故事。Anthropic密集发布近20次重大更新后,年化收入突破300亿美元,但同期,整个市场的估值体系正在剧烈震荡,一家AI公司从“被追捧”到“被审视”的周期,从12-18个月缩短到了3-6个月。
能活过周期的公司,靠的不是参数最猛,而是在真实产业场景里验证过、打磨过、能解决实际问题的能力。
国内“模数共振”行动的出台,等于给这个判断盖了一个官方认证的章。
它传递的信号很清晰:产业AI的建设标准,正在从“模型能力”转向“数据-模型-场景”的闭环能力。
谁能把行业知识结构化,谁能让AI真正理解一条产线、一套流程、一组规则,谁就拿到了下一个阶段的门票。
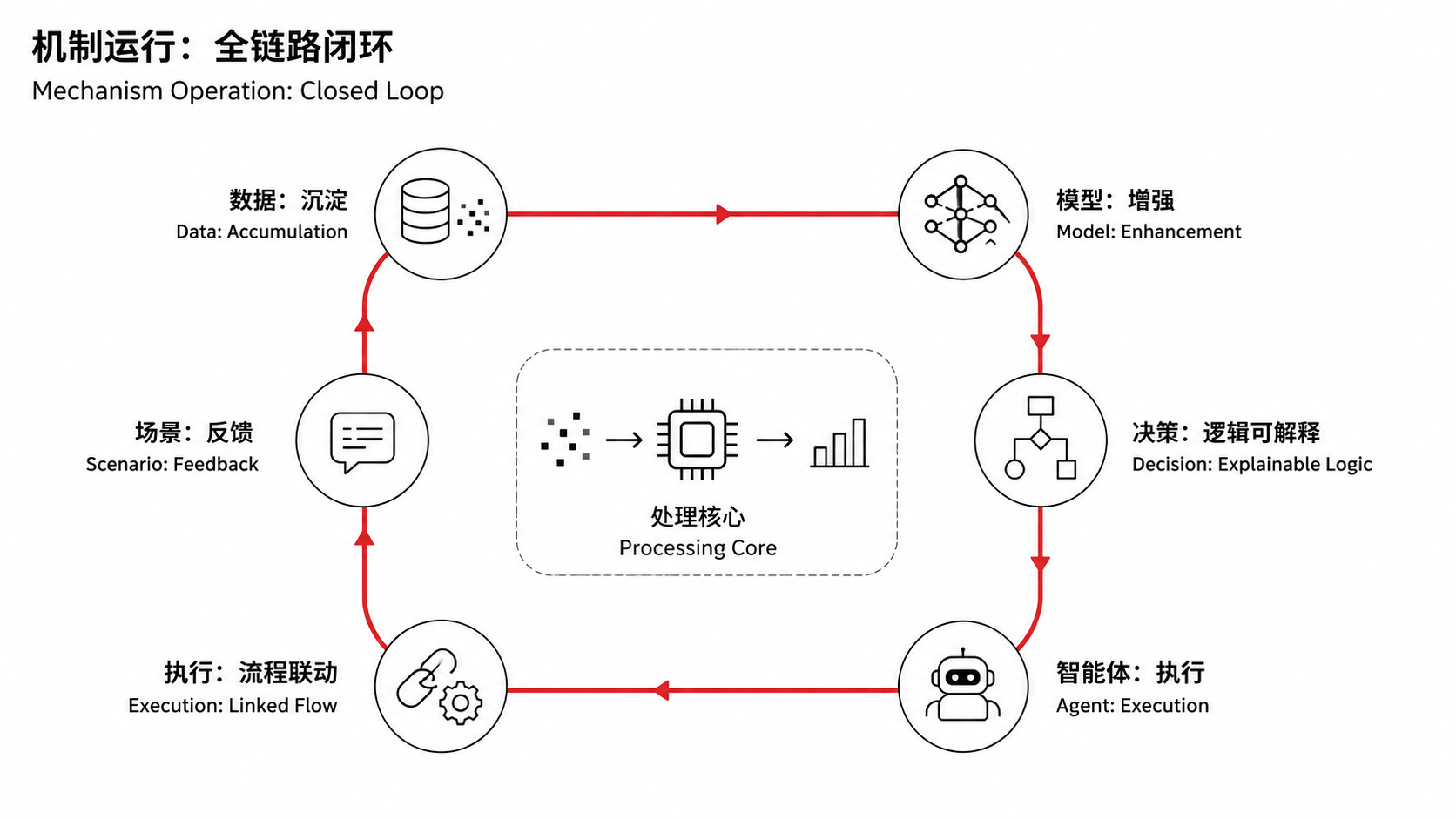
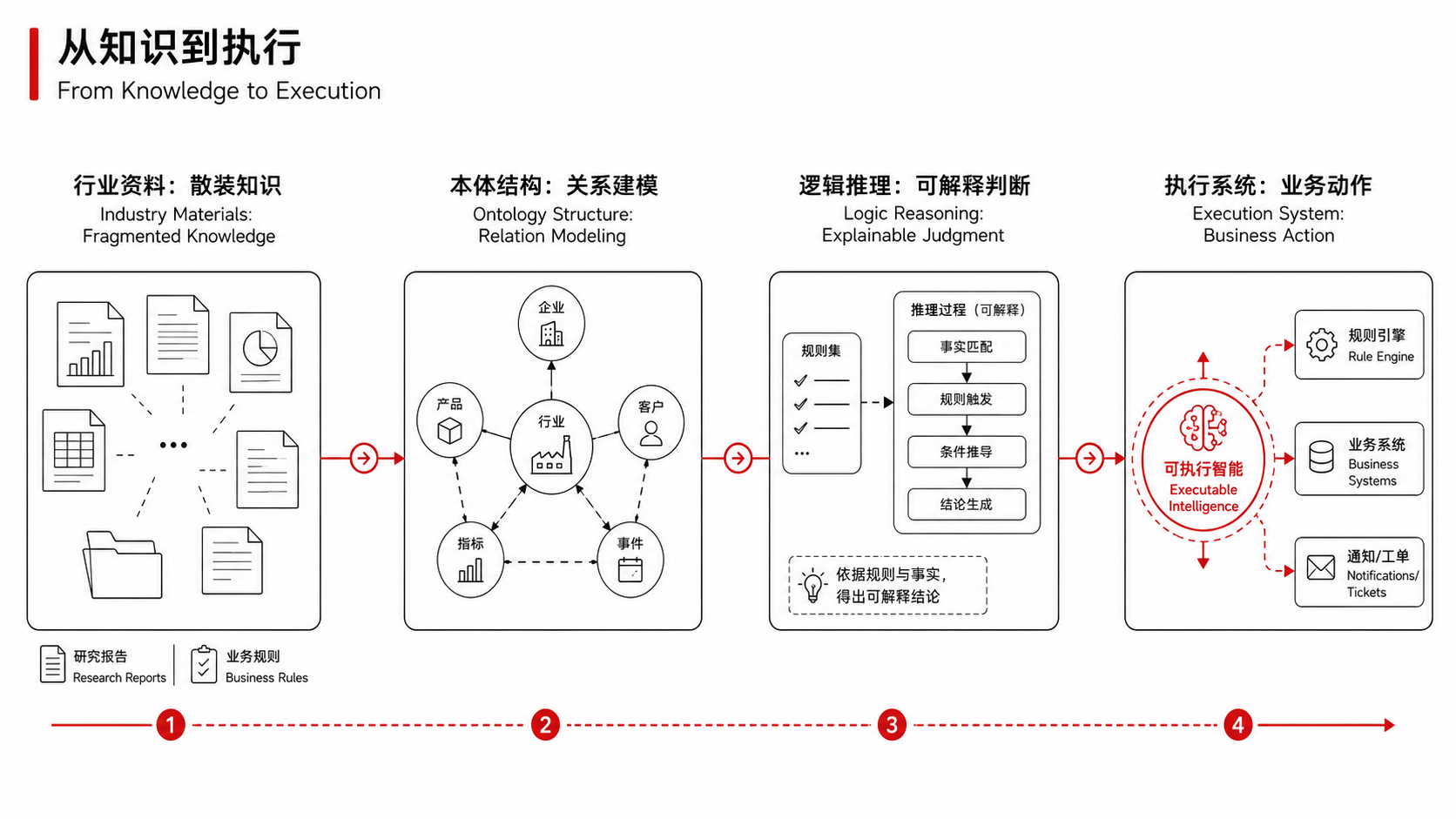
富德数智(FundeAI)成立以来,一直把这样一件事放在我们的核心战略地位:建立“动态本体+AI”的产业智能体系。通俗地讲,就是把行业知识、场景数据、业务流程结构化,变成AI能“读懂、用好”的基础设施。为什么必须先建“本体”?因为当你要处理一条选矿产线的实时数据时,AI不仅要判断数值有没有超出阈值,还要理解这条产线的工艺流程是什么、正常波动范围如何界定、异常信号背后的根因可能在哪——这些都不是通用模型能“推理”出来的,需要行业知识的结构化表达。同理,当你面对一套多层规则叠加的保险理赔流程时,AI需要知道的不只是“条款写了什么”,还有条款之间的优先级关系、历史案例中的执行惯例、地域与险种交叉下的特殊处理逻辑。
这正是“模数共振”所说的:构建行业通识数据集和专识数据集,形成“数据-模型-场景应用”的良性循环。也是我们一直在做的事。富德数智的思路并不是“拿大模型去试业务”,而是反过来——先在真实的产业场景里把知识体系打磨完整,再用AI能力去驱动它。 德真、德渊、德明灯……都是在这个框架下的产物。这条路径比直接调API慢得多,也更考验对行业的理解深度。但它是一条被产业实践反复验证过的、解决“AI在产业里用得好”这个问题的可靠路径。
“模数共振”四个字,很多人第一次听会觉得抽象。但把它翻译成一句大白话,其实很简单:先把行业里的那堆散装知识整理成AI看得懂的样子,再让AI去干活。这个道理不复杂,难的是沉下心来做。当全行业都在为“谁参数更大”欢呼的时候,或许那些愿意蹲在车间里、产线上、业务系统前,一行一行梳理行业知识的人,才最终定义了产业AI能走多远。这可能才是“模数共振”真正带来的变化。
也是富德数智正在参与建设的未来。
富德数智(FundeAI)致力于成为数字经济基础设施提供者和产业智能化发展赋能者。
我们以“人工智能+动态本体”为技术底座,以“算法、算力、数据、安全”为核心,服务金融保险、能源化工、健康管理、智慧政务等多行业领域。从前沿场景出发,把技术转化为可落地的业务成果,助力风险管控、效率提升与智能决策。
我们相信,数智化的价值,在于解决真实世界的复杂问题。